应用健康状态和常见应用异常;
应用健康状态
应用健康状态-使用方式
探测方式
Liveness 指针和 Readiness 指针支持三种不同的探测方式:
- 第一种是 httpGet。它是通过发送 http Get 请求来进行判断的,当返回码是 200-399 之间的状态码时,标识这个应用是健康的;
- 第二种探测方式是 Exec。它是通过执行容器中的一个命令来判断当前的服务是否是正常的,当命令行的返回结果是 0,则标识容器是健康的;
- 第三种探测方式是 tcpSocket 。它是通过探测容器的 IP 和 Port 进行 TCP 健康检查,如果这个 TCP 的链接能够正常被建立,那么标识当前这个容器是健康的。
探测结果
从探测结果来讲主要分为三种:
- 第一种是 success,当状态是 success 的时候,表示 container 通过了健康检查,也就是 Liveness probe 或 Readiness probe 是正常的一个状态;
- 第二种是 Failure,Failure 表示的是这个 container 没有通过健康检查,如果没有通过健康检查的话,那么此时就会进行相应的一个处理,那在 Readiness 处理的一个方式就是通过 service。service 层将没有通过 Readiness 的 pod 进行摘除,而 Liveness 就是将这个 pod 进行重新拉起,或者是删除。
- 第三种状态是 Unknown,Unknown 是表示说当前的执行的机制没有进行完整的一个执行,可能是因为类似像超时或者像一些脚本没有及时返回,那么此时 Readiness-probe 或 Liveness-probe 会不做任何的一个操作,会等待下一次的机制来进行检验。
那在 kubelet 里面有一个叫 ProbeManager 的组件,这个组件里面会包含 Liveness-probe 或 Readiness-probe,这两个 probe 会将相应的 Liveness 诊断和 Readiness 诊断作用在 pod 之上,来实现一个具体的判断。
应用健康状态-Pod Probe Spec
exec:如下图所示,可以看到这是一个 Liveness probe,它里面配置了一个 exec 的一个诊断。接下来,它又配置了一个 command 的字段,这个 command 字段里面通过 cat 一个具体的文件来判断当前 Liveness probe 的状态,当这个文件里面返回的结果是 0 时,或者说这个命令返回是 0 时,它会认为此时这个 pod 是处在健康的一个状态。

httpGet:httpGet 里面有一个字段是路径,第二个字段是 port,第三个是 headers。这个地方有时需要通过类似像 header 头的一个机制做 health 的一个判断时,需要配置这个 header,通常情况下,可能只需要通过 health 和 port 的方式就可以了。

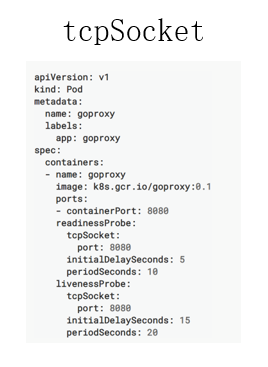
tcpSocket:tcpSocket 的使用方式其实也比较简单,只需要设置一个检测的端口,像下图使用的是 8080 端口,当这个 8080 端口 tcp connect 审核正常被建立的时候,那 tecSocket,Probe 会认为是健康的一个状态。
此外还有如下的五个参数,是 Global 的参数。
- initialDelaySeconds:它表示的是说这个 pod 启动延迟多久进行一次检查,比如说现在有一个 Java 的应用,它启动的时间可能会比较长,因为涉及到 jvm 的启动,包括 Java 自身 jar 的加载。所以前期,可能有一段时间是没有办法被检测的,而这个时间又是可预期的,那这时可能要设置一下 initialDelaySeconds;
- periodSeconds:它表示的是检测的时间间隔,正常默认的这个值是 10 秒;
- timeoutSeconds:它表示的是检测的超时时间,当超时时间之内没有检测成功,那它会认为是失败的一个状态;
- successThreshold:它表示的是:当这个 pod 从探测失败到再一次判断探测成功,所需要的阈值次数,默认情况下是 1 次,表示原本是失败的,那接下来探测这一次成功了,就会认为这个 pod 是处在一个探针状态正常的一个状态;
- failureThreshold:它表示的是探测失败的重试次数,默认值是 3,表示的是当从一个健康的状态连续探测 3 次失败,那此时会判断当前这个pod的状态处在一个失败的状态。
应用健康状态-Liveness 与 Readiness 总结
| Liveness | Readness | |
|---|---|---|
| 介绍 | 用于判断容器是否存活,即Pod状态是否为Running,如果Liveness指针判断容器不健康则会触发kubelet杀掉容器,并根据配置的策略判断是否重启容器,如果默认不配置Liveness探针,则任务返回值默认为成功 | 用于判断容器是否启动完成,即Pod的Condition是否为Ready,如果探测结果不成功,则会将Pod从Endpoint中移除,直至下次判断成功,再将Pod挂回到Endpoint上。 |
| 检测失败 | 杀掉Pod | 切断上层流量到Pod |
| 适用场景 | 支持重新拉起的应用 | 启动后无法立即对外服务的应用 |
| 注意事项 | 不论是Liveness还是Readness探针,选择适合的探测方式可以防止被误操作 1.调大判断的差事阙值,防止在容器压力较高的情况下出现偶发超时 2.调整判断的次数阙值,3次的默认值在短周期下不一定是最佳实践 3.exec的如果执行的是shell脚本判断,在容器中可能调用时间会非常长 4.使用tcpSocket的方式遇到TLS的场景,需要业务层判断是否有影响 |
应用故障排查-了解状态机制
因为 K8S 的设计是面向状态机的,它里面通过 yaml 的方式来定义的是一个期望到达的一个状态,而真正这个 yaml 在执行过程中会由各种各样的 controller来负责整体的状态之间的一个转换。
| Phase | 描述 |
|---|---|
| Pending | Kubernetes 已经创建并确认该 Pod。此时可能有两种情况:Pod 还未完成调度(例如没有合适的节点)正在从 docker registry 下载镜像 |
| Running | 该 Pod 已经被绑定到一个节点,并且该 Pod 所有的容器都已经成功创建。其中至少有一个容器正在运行,或者正在启动/重启 |
| Succeeded | Pod 中的所有容器都已经成功终止,并且不会再被重启 |
| Failed | Pod 中的所有容器都已经终止,至少一个容器终止于失败状态:容器的进程退出码不是 0,或者被系统 kill |
| Unknown | 因为某些未知原因,不能确定 Pod 的状态,通常的原因是 master 与 Pod 所在节点之间的通信故障 |
用故障排查-常见应用异常
pod 上面可能会停留几个常见的状态。
Pod 停留在 Pending
第一个就是 pending 状态,pending 表示调度器没有进行介入。此时可以通过 kubectl describe pod 来查看相应的事件,如果由于资源或者说端口占用,或者是由于 node selector 造成 pod 无法调度的时候,可以在相应的事件里面看到相应的结果,这个结果里面会表示说有多少个不满足的 node,有多少是因为 CPU 不满足,有多少是由于 node 不满足,有多少是由于 tag 打标造成的不满足。
Pod 停留在 waiting
那第二个状态就是 pod 可能会停留在 waiting 的状态,pod 的 states 处在 waiting 的时候,通常表示说这个 pod 的镜像没有正常拉取,原因可能是由于这个镜像是私有镜像,但是没有配置 Pod secret;那第二种是说可能由于这个镜像地址是不存在的,造成这个镜像拉取不下来;还有一个是说这个镜像可能是一个公网的镜像,造成镜像的拉取失败。
Pod 不断被拉取并且可以看到 crashing
第三种是 pod 不断被拉起,而且可以看到类似像 backoff 。这个通常表示说 pod 已经被调度完成了,但是启动失败,那这个时候通常要关注的应该是这个应用自身的一个状态,并不是说配置是否正确、权限是否正确,此时需要查看的应该是 pod 的具体日志。
Pod 处在 Runing 但是没有正常工作
第四种 pod 处在 running 状态,但是没有正常对外服务。那此时比较常见的一个点就可能是由于一些非常细碎的配置,类似像有一些字段可能拼写错误,造成了 yaml 下发下去了,但是有一段没有正常地生效,从而使得这个 pod 处在 running 的状态没有对外服务,那此时可以通过 apply-validate-f pod.yaml 的方式来进行判断当前 yaml 是否是正常的,如果 yaml 没有问题,那么接下来可能要诊断配置的端口是否是正常的,以及 Liveness 或 Readiness 是否已经配置正确。
Service 无法正常的工作
最后一种就是 service 无法正常工作的时候,该怎么去判断呢?那比较常见的 service 出现问题的时候,是自己的使用上面出现了问题。因为 service 和底层的 pod 之间的关联关系是通过 selector 的方式来匹配的,也就是说 pod 上面配置了一些 label,然后 service 通过 match label 的方式和这个 pod 进行相互关联。如果这个 label 配置的有问题,可能会造成这个 service 无法找到后面的 endpoint,从而造成相应的 service 没有办法对外提供服务,那如果 service 出现异常的时候,第一个要看的是这个 service 后面是不是有一个真正的 endpoint,其次来看这个 endpoint 是否可以对外提供正常的服务。
开源的调试工具 - kubectl-debug
kubectl-debug 这个工具是依赖于 Linux namespace 的方式来去做的,它可以 datash 一个 Linux namespace 到一个额外的 container,然后在这个 container 里面执行任何的 debug 动作,其实和直接去 debug 这个 Linux namespace 是一致的。
总结
- 关于 Liveness 和 Readiness 的指针。Liveness probe 就是保活指针,它是用来看 pod 是否存活的,而 Readiness probe 是就绪指针,它是判断这个 pod 是否就绪的,如果就绪了,就可以对外提供服务。这个就是 Liveness 和 Readiness 需要记住的部分;
- 应用诊断的三个步骤:首先 describe 相应的一个状态;然后提供状态来排查具体的一个诊断方向;最后来查看相应对象的一个 event 获取更详细的一个信息;
- 提供 pod 一个日志来定位应用的自身的一个状态;
- 远程调试的一个策略,如果想把本地的应用代理到远程集群,此时可以通过 Telepresence 这样的工具来实现,如果想把远程的应用代理到本地,然后在本地进行调用或者是调试,可以用类似像 port-forward 这种机制来实现